

10 лет назад в Санта-Клара, Калифорния, неподалеку от Интела и NVidia, стоял кампус Huawei. В нем работали не только китайцы, но и вообще обычная публика Silicon Valley – индусы, американцы, даже русские попадались. Бизнесмены калифорнийских электронных компаний говорили “Huawei – это дверь в Китай” и заключали с ними крупные сделки.
Но американское правительство Huawei невзлюбило. Можно обсусоливать те или иные поводы, но коренная причина понятна – американскому правительству хочется, чтобы Америка сохраняла технологическое преимущество. Ибо если технология коммодифицируется и айфон не будет ничем особенным, то кто будет читать брошурки про продвижение демократии, распостраняемые американскими посольствами в других странах? Над ними будут просто смеяться.
И вот правительство начало Huawei жучить – и от Андроида отлучило, и от других критических технологий. Но на всяких хитрецов найдется гайка с левой резьбой. И вот что Huawei стал делать по этому поводу.
Но начнем по порядку. Вот как выглядел кампус Huawei на пересечении Central Expressway с San Tomas Expressway (Центральное Шоссе и Шоссе Святого Фомы Аквинского) в Санта-Кларе:

Я в эти здания заходил, так как работал с Huawei в совместном проекте от лица MIPS и даже получил за это табличку на стену:

Про сам проект прессе были известны только слухи, хотя с Huawei / HiSilicon работал не только MIPS, но и например IBM Microelectronics. Про IBM я узнал совершенно случайно, наткнувшись на инженера из этого проекта во время отпуска в Юте. Главное СМИ электронной промышленности, Electronic Engineering Times, писало про проект загадочно, в рубрике EE Times Confidential:
Потом настало это:

Но Huawei – не такая компания, чтобы покорно ползти в могилу из-за каких-то госдеповских бюрократов. Они бодро начали импортозамещение, в том числе в области программ для проектировщиков микросхем, и сразу наняли 50 молодых PhD на разработку алгоритмов EDA (Electronic Design Automation – автоматизация проектирования электроники, по русски САПР):
Я вспомнил про случай Huawei / HiSilicon, когда на днях мне прислал емейл Андрей Садовых из казанского Иннополиса и попросил придумать задачку для их хакатона по программам автоматизации проектирования CASE in Tools 2022.
Я уже участвовал в таком хакатоне как задачкодатель в 2020 году и описал задачку по трассировке и размещению логических элементов микросхемы на Хабре (пост до хакатона и после). Вот команда, которая решила мою задачку и получила приз:


Итак, новая задачка. Назовем ее “Подсчет количества D-триггеров в схеме на основе анализа кода на языке описания аппаратуры SystemVerilog (без учета оптимизации)“.
Немного картины с высоты птичьего полета.
Разработчика блока микросхемы оценивают не только по отсутствию функциональных багов, но и по PPA – Power-Performance- Area или Энергопотребление-Производительность-Площадь. При этом:
- В энергопотреблении выделают статическое (все время) и динамическое (пропорционально переключениям, зависит от конкретного теста);
- Производительность разделяют на пропускную способность (сколько транзакций проходит через блок за N тактов) и тактовую частоту (1 / сколько длится такт);
- Площадь делят на размер блоков встроенной статической памяти и площадь под стандартные ячейки.
Для грубой оценки площади под стандартные ячейки в микросхемах ASIC удобно использовать количество D-триггеров, минимальных элементов состояния / памяти. Это связано с тем, что пропорция ячеек комбинационной логики к количеству D-триггеров во многих типах схем статистически сходна и именно количество D-триггеров является узким местом. В FPGA ситуация несколько другая – там D-триггеров по сравнению с комбинационной логикой много и их не нужно так сильно экономить как в ASIC-ах.
Количество D-триггеров важно еще и потому, что своими переключениями они жрут много электроэнергии.
Короче, на проектировщика блока архитекторы чипа как правило спускают:
- Функциональную/архитектурную спецификацию;
- Требования к пропускной способности;
- Бюджет тактовой частоты;
- Бюджет количества D-триггеров;
- Общий бюджет площади, включающей площадь блоков статической памяти;
- Пожелания понизить энергопотребление по сравнению с предыдущим блоком на столько-то процентов.
Суть задачи
Подсчитать количество комбинационных логических элементов в схеме, описанной на языке SystemVerilog – это однозначно не хакатонная задача – она требует сложной технологии логического синтеза. Но вот количество D-триггеров подсчитать гораздо проще – достаточно найти в коде все так называемые неблокирующие присваивания и суммировать размеры всех переменных, к которым они применяются.
Варианты задачи разной сложности
Разумеется, при этом возникает много трудностей. В зависимости от формулировки задачу подсчета D-триггеров на основе кода можно решить за любое время от 1 часа до 1 года. Перечислим эти трудности (потом мы перечислим их снова, но уже с картинками):
- Разработчик / писатель кода на верилоге мог по неаккуратности использовать блокирующие, а не неблокирующие присваивания. Мы не рассматриваем этот вариант – мы будем считать, что писатель кода жестко следовал рекомендуемой методологии проектирования.
- Для простейшего варианта хакатона (на час) можно написать простой скрипт на питоне, который будет работать только если все переменные явлются однобитными; для более интересного хакатона (на день) стоит рассматривать многобитовые вектора; для еще более интересного (на пару дней) – многомерные массивы, а для варианта на год – все структуры данных в языке SystemVerilog.
- Для целей хакатона вероятно стоит парсировать код, в котором не используются директивы препроцессора (`define), нет параметризации (parameter, localparam) и нет конструкции generate. Хотя если реализация на хакатоне делается на основе существующего open-source парсера верилога (например из Icarus Verilog или из Yosys), то можно попробывать обрабатывать код и со всеми этими конструкциями.
- Для простого хакатона наверное стоит подсчитывать D-триггеры только в одном модуле. Для более сложного стоит парсировать и модульную иерархию.
Инструментарий
Мне честно говоря самому интересно, до чего дойдут студенты. Как я уже сказал:
1) Простейший вариант (без иерархии, параметризации и с однобитовыми переменными) можно написать на языке типа питона или джавы за час.
2) Если использовать многобитовые переменные и многомерные массивы, на решение может уйти еще полдня, но того же питона тоже должно хватить. Возможно понадобиться применить регулярные выражения.
3) Модульная иерархия вносит дополнительные сложности. Помимо быстрого кодирования на питоне или джаве (на что может уйти день) стоит рассмотреть вариант освоить чужой парсер верилога на C++ (Icarus Verilog или Yosys) и модифицировать его для этой задачи.
Иллюстрации частных случаев
Теперь то же самое, но с картинками. Первые два модуля вообще не содержат никаких D-триггеров – в них нет ни always-блока по фронту, ни неблокирующих присваиваний (“<=”). Только блокирующее внутри “always_comb” (“=”) :

Такая схема синтезируется в двух-входовый логический элемент И:
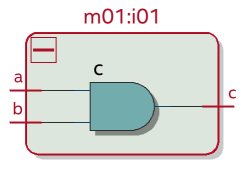
А вот как выглядит код, порождающий D-триггер. В нем есть неблокирующее присваивание (“<=”) к переменной “c” которая объявлена как выходной порт и имеет размер 1 бит.
Неблокирующее присваивание находится внутри always-блока по фронту тактового сигнала (хакатонное решение может игнорировать этот факт, обращая внимание только на переменную, к которой применяется неблокирующее присваивание).
Также важно не спутать неблокирующее присваивание с операцией “меньше или равно” которая тоже пишется как “<=”.

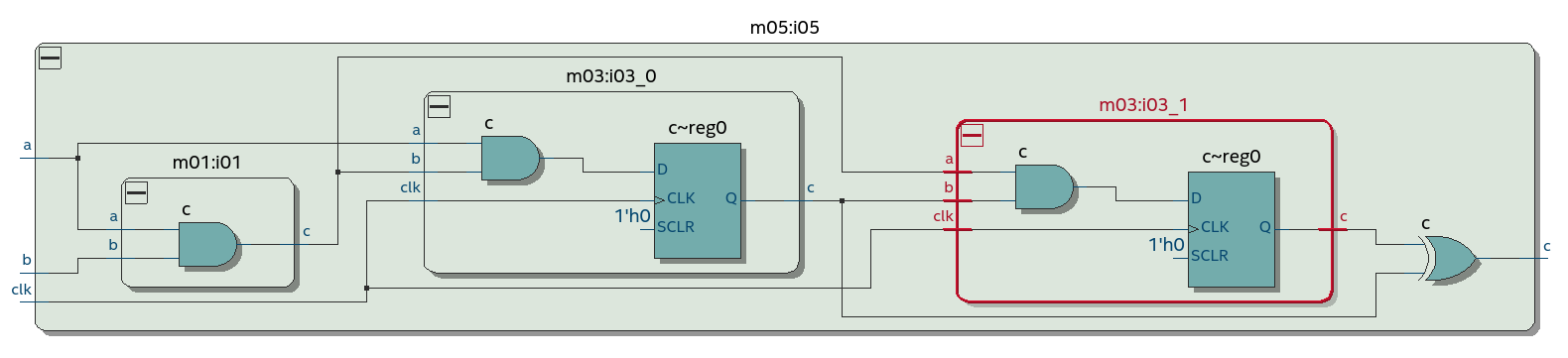
Этот код соответствует следующей схеме. Квадратик на ней – это D-триггер:
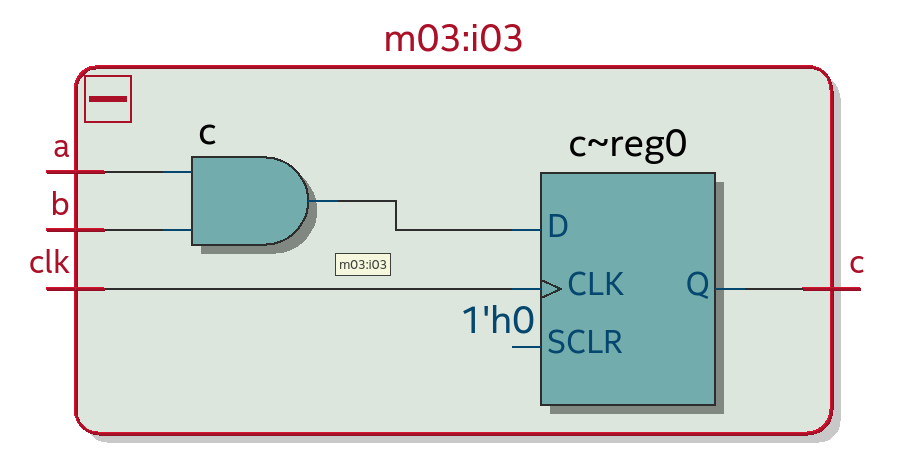
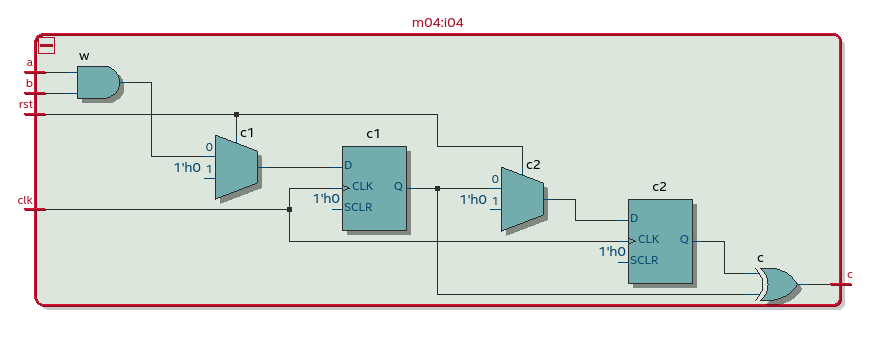
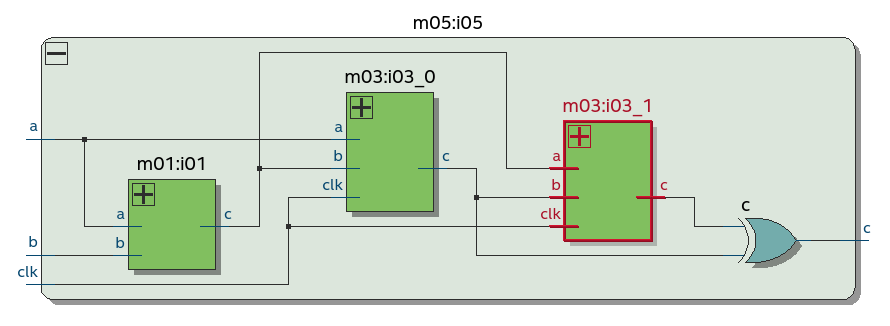
Несколько неблокирующих присваиваний к одной и той же переменной не порождают несколько D-триггеров. Но неблокирующие присваивания к разным переменным – порождают. В примере слева неблокирующие присваивания делаются двум однобитовым переменным, что порождает два D-триггера. Синхронные сбросы у этих D-триггеров перед оптимизацией превращаются в мультиплексоры, но это не важно для нашей цели подсчета D-триггеров:

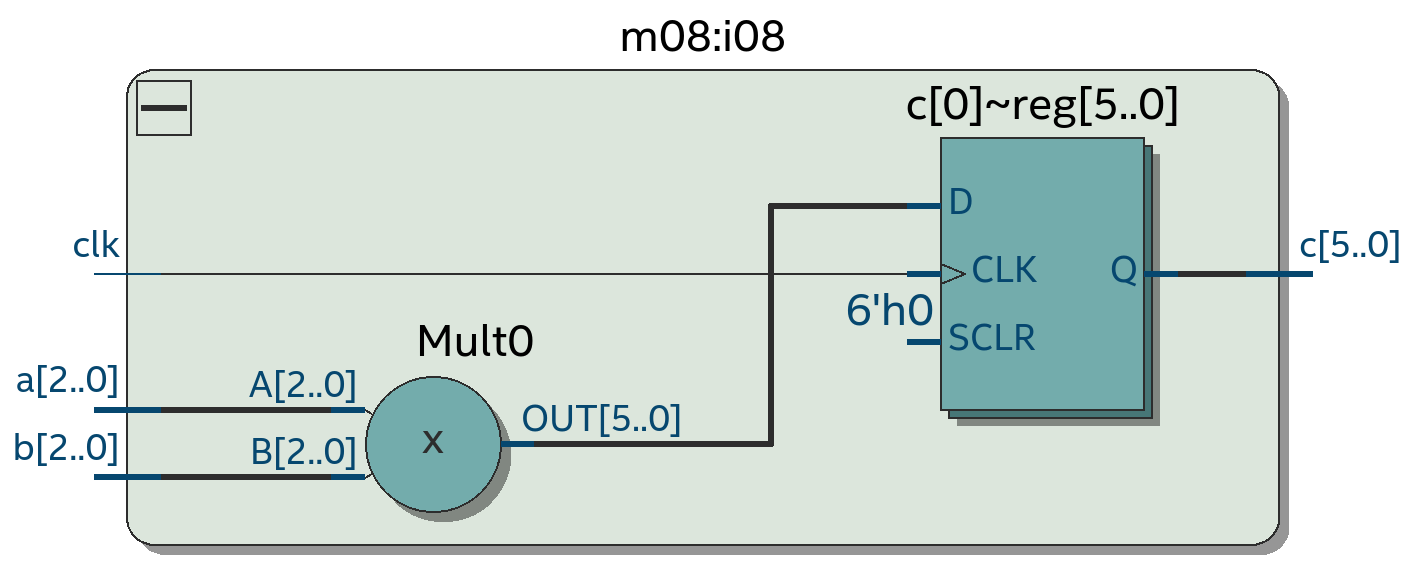
Следующее усложнение хакатона – это добавление переменных шириной в несколько бит. В примере ниже результат умножения двух 3-битных чисел “a” и “b” помещается в регистр “c” шириной 6 бит. Регистр – это просто группа из D-триггеров, которая в данном случае состоит из D-триггеров c[5], c[4], c [3], c [2], c[1] и c[0]:

Если усложнить задачу вне рамок хакатона, такой модуль можно параметризовать – либо с помощью препроцессора (слева), либо с помощью ключевого слова “parameter” справа:

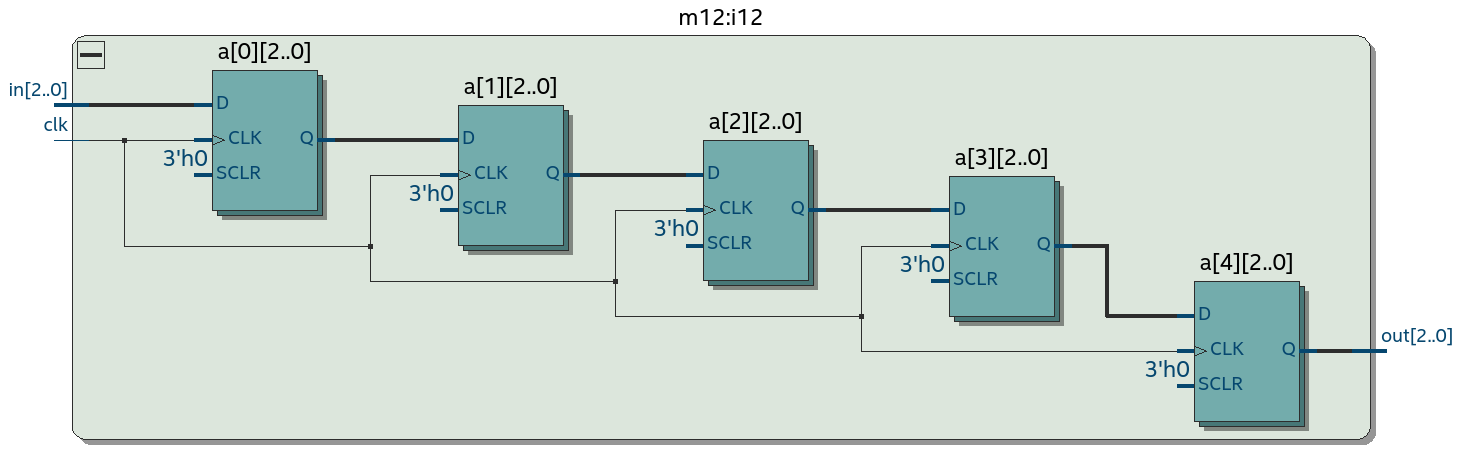
Другое важное усложнение, которое стоит сделать во время хакатона – это неупакованные массивы с размерностью справа от идентификатора. Слева пример схемы сдвигового регистра шириной 3 бита и глубиной 5 элементов, который использует 3 * 5 = 15 D-триггеров.

Вот как выглядит схема такого сдвигового регистра, обратите внимание что D-триггеры одного элемента собраны в “книжечки” по 3:
Стандарт SystemVerilog также поддерживает синтаксис “logic [2:0] a [5]” вместо “logic [2:0] a [0:4]”. Вне рамок хакатона можно было бы написать программу, которая подсчитывает D-триггеры для сложных типов данных, например структур:

Наконец, было бы хорошо (возможно не на хакатоне, а после него) написать программу, которая бы парсировала иерархию модулей и подсчитывала D-триггеры на всех уровнях. Модули в верилоге как матрешки, за исключением того, что одной и той же матрешки может быть несколько экземпляров – D-триггеры во всех экземплярах нужно суммировать, это не как в софтвере с вызовами функций;

А вот случай использования конструкции generate. Его имхо можно покрыть на хакатоне только если использовать чей-то готовый open-source парсер:

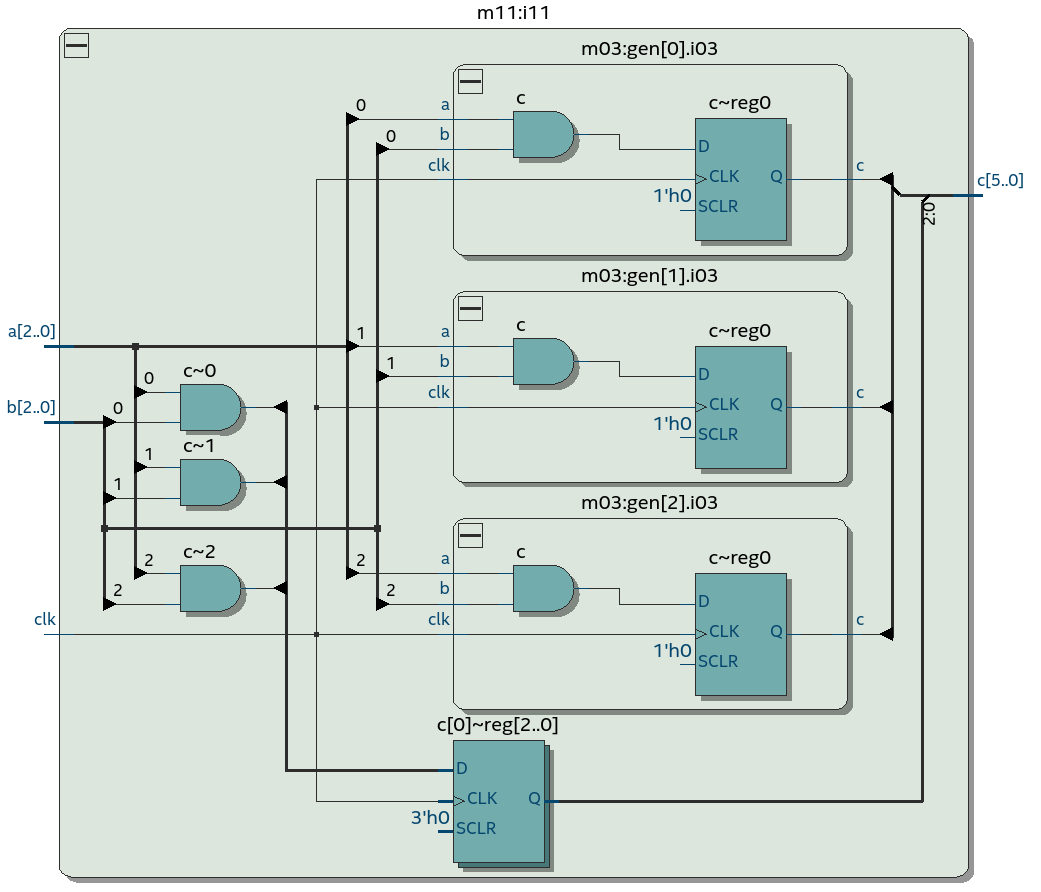
То что выглядит синтаксически как софтверный цикл – на самом деле не цикл, а своего рода макро, порождающее несколько экземпляров модуля m03 (D-триггеры в них нужно суммировать).
В этой схеме при w=3 будет шесть D-триггеров – три из always-блока на верхнем уровне и три из трех экземпляров модуля второго уровня m03.
Я надеюсь, что какая-нибудь команда в Иннополисе не напугается и примет мою задачу. Она, при разумной формулировке, проще, чем может показаться из моей заметки. В худшем случае можно сделать “grep ‘<=’ | sed … | sort -u | wc -l” – и объявить задачу выполненной (это вполне ответ для формулировки задачи без иерархии и с однобитовыми переменными).
Так что успехов и вперед. Это поможет вам нарастить скиллы в компиляторах, скриптинге и разумеется основах цифрового проектирования – очень ценный рабочий навык в современной международной обстановке.